
Learning to Segment Human Body Parts with Synthetically Trained Deep Convolutional Networks
Alessandro Saviolo, Matteo Bonotto, Daniele Evangelista, Marco Imperoli,
Jacopo Lazzaro, Emanuele Menegatti, Alberto Pretto

Abstract. This paper presents a new framework for human body part segmentation based on Deep Convolutional Neural Networks trained using only synthetic data. The proposed approach achieves cutting-edge results without the need of training the models with real annotated data of human body parts. Our contributions include a data generation pipeline, that exploits a game engine for the creation of the synthetic data used for training the network, and a novel pre-processing module, that combines edge response maps and adaptive histogram equalization to guide the network to learn the shape of the human body parts ensuring robustness to changes in the illumination conditions. For selecting the best candidate architecture, we perform exhaustive tests on manually annotated images of real human body limbs. We further compare our method against several high-end commercial segmentation tools on the body parts segmentation task. The results show that our method outperforms the other models by a significant margin. Finally, we present an ablation study to validate our pre-processing module.
Introduction
The ability to extract human body parts from the foreground space of images is an essential requirement for many robotics and perception applications such as human-robot interaction, surgical robotics, and medical images analysis, self-perception in mixed reality, and 3D human body reconstruction. A collaborative robot, for example, should be able to localize the arms of the human operator with whom it is collaborating, just as a surgical robot must be able to accurately locate the limb on which it is operating. In egocentric vision systems, hand position recognition is a key capability, for example, to detect which objects come into contact with it. 3D human body reconstruction systems must be able to distinguish which parts of the input images belong to the human body, and which parts must not be considered in the reconstruction.
The body parts localization task can be addressed as a semantic segmentation problem. Semantic segmentation aims to provide a per-pixel classification of the input image. In the specific case of human body segmentation, there are two classes involved: pixels that belong to human limbs and those that do not. Semantic segmentation of naked human body parts can be obtained, for instance, by exploiting skin color detection and segmentation techniques. Unfortunately, such color-based systems suffer from severe robustness problems due to the variability of skin tone, the variability of light conditions, and the complexity of backgrounds, which can be mistaken for portions of the skin.
Convolutional Neural Networks (CNNs) are convenient and effective methods for addressing the general problem of semantic segmentation. Multiple powerful networks have been proposed to obtain superior segmentation results. Unfortunately, these segmentation techniques require thousands of annotated images to be properly trained. Manually labeling the entire dataset is challenging and extremely time-consuming. Furthermore, the quality of the segmentation result in the case of human body parts obtained by most CNN-based systems is fair but certainly not adequate for many of the applications listed above. Background removal systems can be used for body part localization as well: unfortunately, such systems either require a rich prior knowledge about the scene to build an accurate background model or are too general and struggle to adapt to specific tasks. Other techniques, such as background subtraction in a green screen setting, allow to speed up the annotation process. However, they may come at the cost of the unrealistic feature of green color bleeding at the annotation boundaries.
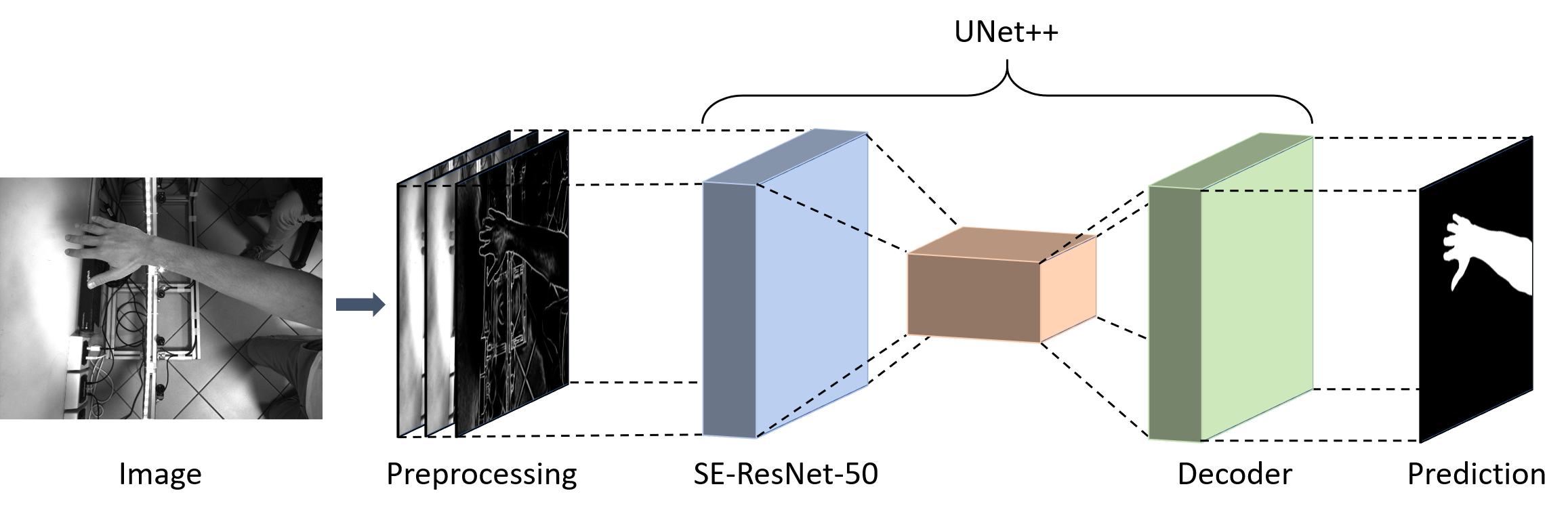
Contributions. This paper proposes a new framework for body part segmentation (Fig. 2) that aims to overcome the limitations listed above. The proposed framework has been specifically trained to obtain highly accurate segmentation masks from images of naked human limbs without the need for any real data annotation since it only relies on synthetically generated data and a custom pre-processing of the network's input. Our system is based on a pipeline that includes a state-of-the-art semantic segmentation architecture and a custom pre-processing module that feeds the segmentation network with a specific input tensor built by concatenating the edge response map and two equalized versions of the original input image. The pre-processing module is designed to polarize the network to focus on the shape of the objects of interest (human limbs in our case) rather than the skin tone (intensity or color) or its characteristic texture. This simple modification greatly increases the level of segmentation accuracy compared to the same network fed with raw input images. Moreover, to emphasize skin tone independence, we performed all the experiments considering gray-level images. Our system also does not require any manually annotated data for training. The data are automatically generated by rendering, with a game engine, synthetic photo-realistic views of human limbs: such images are provided with ground truth segmentation masks (i.e., the annotations) at no additional cost. The geometric properties of human limbs (e.g., scale, deformation) and the scene configuration (e.g., illumination, camera positions) are defined by a set of parameters. By randomly choosing a combination of these parameters within predefined ranges, our data generation pipeline can generate multiple unique synthetic images and their corresponding annotations. We report an exhaustive performance evaluation, focusing on the arm segmentation use case. Experiments have been performed on a custom-built, manually labeled dataset that includes several views of real human arms. Our experiments aim both to validate the architectural choices and to show that our system overcomes by a large margin several state-of-the-art segmentation architectures in the specific human limb segmentation task. Furthermore, we compare our method against several cutting-edge commercial foreground segmentation networks on the body parts segmentation task and demonstrate that the considered networks are too generic to produce accurate segmentation results.
Method
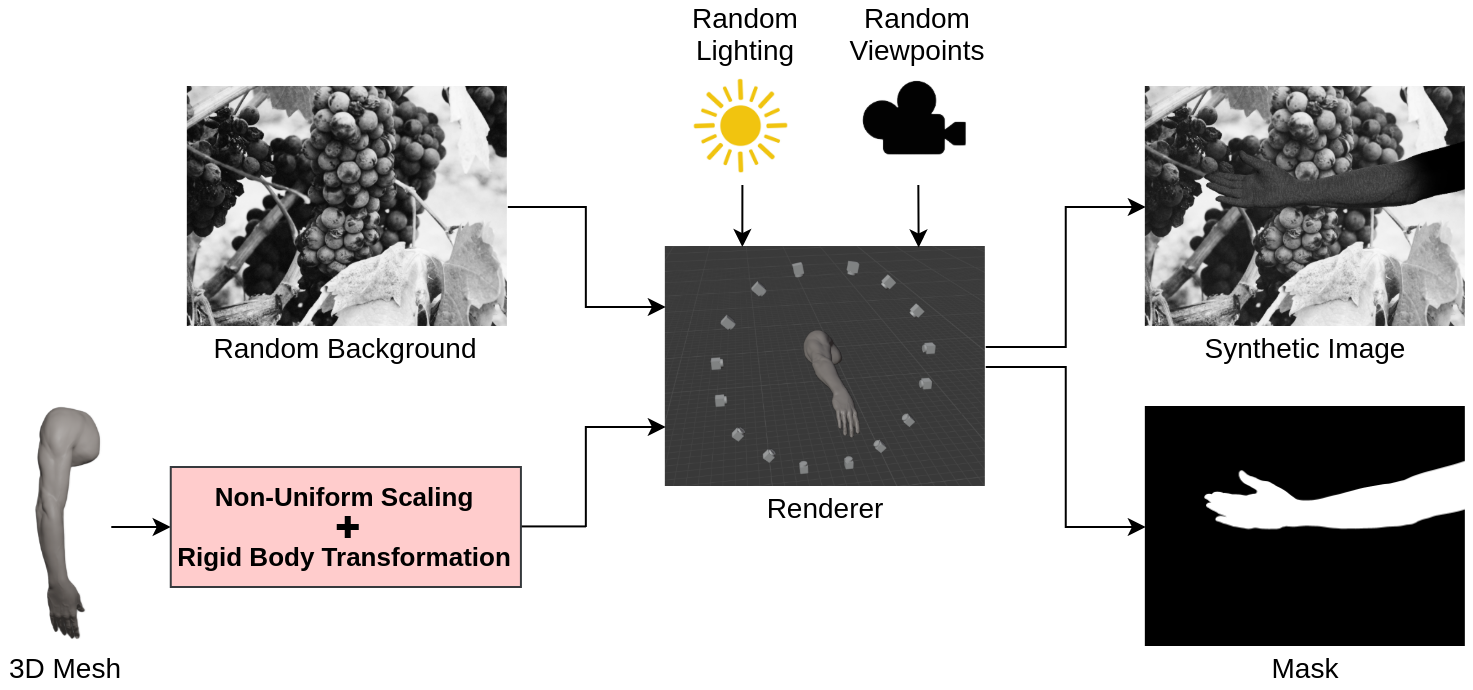
Body-Part Synthetic Data Generation. The front-end of our framework is a synthetic data generation pipeline that enables us to produce efficiently and effectively synthetic annotated images for training and evaluating segmentation networks. The input of our pipeline (Fig. 3) is a set of 3D meshes of human limbs. Each mesh is positioned with a random location and orientation in an empty scene. A random number of different types of lighting sources are inserted at random locations in the scenes. Each scene is framed by multiple virtual cameras positioned in random viewpoints. For every acquired view, we sample from a uniform distribution the location and orientation of the framed limb, and the positions and intensity of the light sources. We also apply to the limbs a non-uniform scaling transformation, with the directional scaling factors s_x, s_y, s_z sampled from a uniform distribution. Moreover, we apply to each limb a random texture defined by multiple shades of gray and irregular dark dots representing skin flaws (e.g., moles). Finally, each image is stored with the corresponding annotation, which is computed by rendering the limb on a black background and then applying a binary threshold to the image. The synthetic data generation pipeline pursues two objectives: i) Maximize the variability of the data, since, with enough variability in the simulated environment, the real-world may appear as just another variation of the synthetic scene; ii) Emphasize the shape of the mesh in the images, to guide the networks at training time to focus on relevant features, ignoring useless details that negatively affect the quality of the predictions. The first objective is achieved by defining the geometric properties of human limbs and the scene configuration by a set of parameters, and then randomly choosing a combination of these parameters within predefined ranges. The second objective is achieved by adopting a domain randomization strategy. By applying random backgrounds to the images, networks are forced to focus at training time on the shape of the object of interest and ignore other objects in the scene (i.e., networks better learn to focus on the relevant features, rather than the skin tone or its characteristic texture).
Shape-Aware Segmentation. The proposed segmentation framework is based on a state-of-the-art segmentation network and a custom pre-processing module. Such a module feeds the segmentation network with a specific input tensor built by concatenating the edge response map and two equalized versions of the input image. To induce the segmentation networks to minimize the generation of artifacts in the segmentation masks, we propose to augment the input of the segmentation networks with an edge map extracted from the image. Such augmentation aims to induce the network to focus on the shape of the human limbs to be segmented, rather than the skin tone (intensity or color) or its characteristic texture. Specifically, we extract from the image a map that for each pixel encodes the edge responses, that is a real value ranging from 0 (no edge) to 1 (maximum probability that the pixel is an edge). We call this map edge response map, to distinguish it from a binarized edge map. To make the segmentation networks more robust against the variability of light conditions, we propose to replace the input image with its equalized version. By equalizing the input image, we improve the contrast and therefore the invariance under different light conditions. The edge response map and the equalized image are then concatenated and fed to the segmentation network. This simple modification enables a considerable increase in the level of segmentation accuracy compared to the same segmentation network fed with raw input images. Our pre-processing module (Fig. 2) relies on the Holistically-Nested Edge Detection (HED) method to extract the edge response map. HED is a CNN-based edge detection system that enables cutting-edge performance by combining multi-scale and multi-level visual responses: this allows it to be independent of the scale of the objects whose border is to be extracted. Histogram equalization is obtained by exploiting the Contrast Limited Adaptive Histogram Equalization (CLAHE) method. CLAHE is an adaptive method that computes several local histograms, each corresponding to a specific image portion, so it is well suited for improving the contrast also in images that present different lighting conditions inside them. To avoid amplifying noise, CLAHE applies contrast limiting: if any histogram bin is greater than a contrast threshold, the corresponding pixels are distributed uniformly to other bins before applying histogram equalization. To be more independent of this threshold, in our system we apply two different contrast thresholds and concatenate the two resulting images with the edge response map extracted with HED. The generated tensor is finally given as input to the UNet++ segmentation network, which from our tests resulted in the best segmentation network when applied to human body parts. To validate the composition of our input tensor, we performed an exhaustive ablation study showing superior results when comparing with alternative combinations.
Experiments
Human Arm Segmentation. We analyze and compare the results generated by our system and several cutting-edge commercial software widely known for their accurate performances on the foreground segmentation task. Figure 4 shows the segmentation masks produced by our method and several commercial software available on the Web, namely RemoveBG, Pixlr, Slazzer, Photoshop, RemovalAI, and PhotoScissors. The results show that the commercial tools for foreground segmentation are capable of accurately extracting the foreground objects from single input images without relying on prior knowledge about the scene. However, these methods are too generic and can not be used to focus only on a specific object in the foreground space, such as human body parts. On the contrary, our method is specifically tailored to our task and learns to segment human body parts accurately and robustly. By leveraging the shape information of the human limbs, the proposed method is robust to the variability of skin tone, the variability of light conditions, and the complexity of backgrounds.

Multi-stereo 3D Reconstruction. We evaluate the proposed segmentation method in the 3D reconstruction's context. A 3D-printed human arm has been reconstructed using a custom-built multi-camera acquisition device. Figure 5 illustrates the influence of our body parts segmentation method in the 3D reconstruction of human arms. The integration of accurate input masking into the reconstruction pipeline leads to a reduction in noise and outliers in 3D estimation, especially in the challenging fingers regions.

Discussion and Conclusions
In this paper, we proposed a novel framework for human body part segmentation, based on state-of-the-art Deep Convolutional Neural Networks, that does not require manually annotated data. Training data is automatically generated by rendering with a game engine synthetic, but photo-realistic, views of human limbs. Random geometric non-rigid transformations are applied to the rendered models as well as different illumination conditions. In this way, the proposed data generation pipeline can generate multiple unique synthetic images and their corresponding annotations. A pre-processing module that combines an edge response map with equalized versions of the input image has been specifically designed to polarize the network to focus on the shape of the objects of interest (human limbs in our case) rather than the skin tone (intensity or color) or its characteristic texture. Exhaustive performance evaluations on a custom-built, manually labeled dataset that includes several views of real human arms show the effectiveness of our method.
Acknowledgment
This work was part of E-Cast, a joint project between FlexSight and PlayCast with the goal to offer the best alternative to traditional plaster. This project has received funding from the DIGI-B-CUBE voucher framework which has been supported by the European Union’s Horizon 2020 research and innovation program under grant agreement No 824920. Part of this work has been supported by MIUR (Italian Minister for Education) under the initiative “Departments of Excellence” (Law 232/2016).

